
Technology
Extreme Quantization
Nowadays, many open-sourced libraries support INT8 quantization and inference for faster computation. However, we are not satisfied with INT8 precision. We further compress both weights and activations of AI models to sub-4-bit precisions. We have broken down the technical barriers to sub-4-bit quantization with our novel AI model compression techniques and inference engine. Our AI model compression algorithm finds the optimal precision of each layer in a given AI model, reducing inference latency while maintaining model accuracy. Our inference engine enables efficient sub-4-bit computation on various platforms from Arm CPUs to GPUs.
Compressing Neural Networks
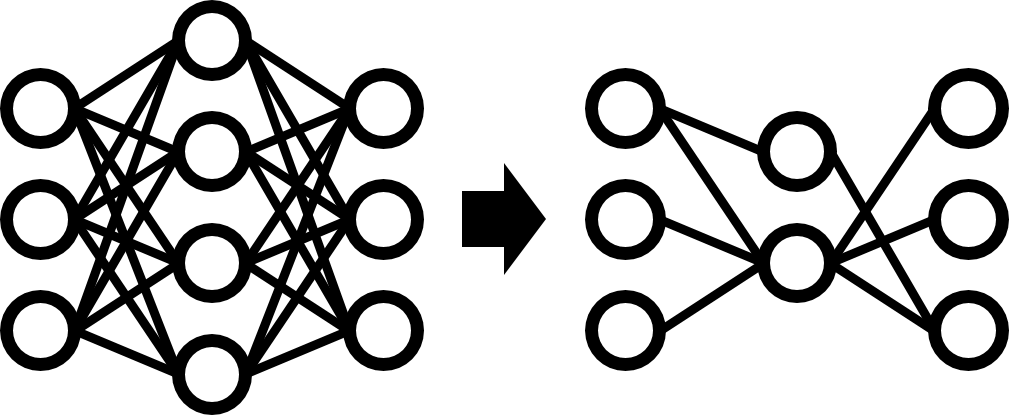
Most of the recent improvements on AI performance have become possible with the significant growth in the scale of AI models. However, running such large AI models on edge devices (or even on GPU devices) is cumbersome, limiting innovations in daily lives.
We compress AI models using state-of-the-art techniques including quantization, pruning, knowledge distillation and AutoML. With our techniques, we develop highly compressed AI models while preserving accuracy.
Accelerating AI Inference
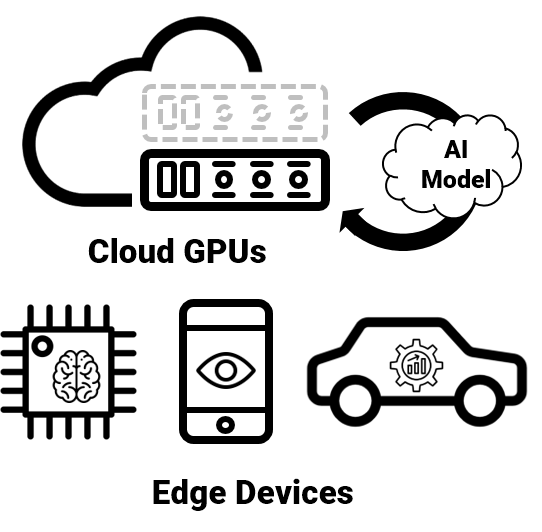
Compressing AI models alone is not enough for best performance. Accelerating inference of compressed AI models with an appropriate inference engine is also essential.
Our inference engine enables much faster inference on edge CPUs and GPUs with fully-optimized kernels. With auto-compilation technique, we find the best way of computing AI models with low cost.
Pre-trained Model Zoo
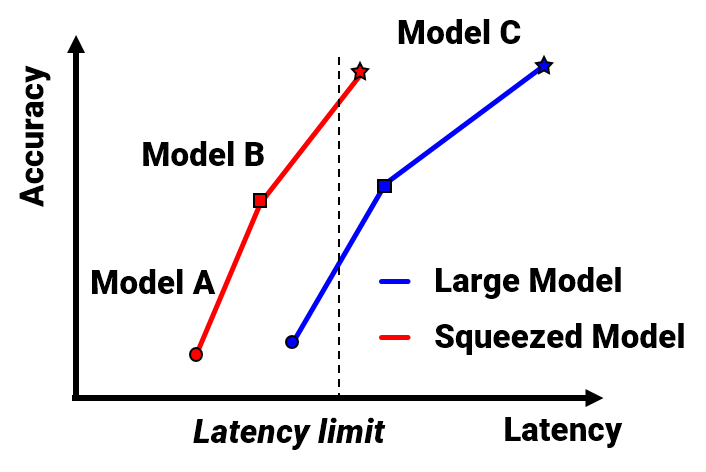
We provide pre-trained and pre-compressed AI models on various deep learning tasks including Computer Vision and NLP. Users can select a model from the Model zoo and fine-tune it to their task to meet the required accuracy and latency conditions.